How to Add AI to Your Existing Systems Without Rebuilding Everything
How to Add AI to Your Existing Systems Without Rebuilding Everything
March 19, 2026
A Software Development Perspective on Augmentation Patterns, Integration Risk, and Practical Deployment for your team or the one you hire
The instinct to rebuild from scratch when adopting AI is understandable, but it is rarely the right call. Most enterprise platforms — CRMs, ERPs, internal tools, and custom-built applications — contain years of accumulated business logic, workflow configuration, and operational data that cannot simply be exported and re-imported into a new system. A full rebuild carries real costs: extended timelines, data migration risk, staff retraining, and a period of reduced operational capacity that most organizations cannot afford.
The more effective path, and the one most mature engineering teams now take, is augmentation — layering AI capabilities onto existing infrastructure without disrupting what already works.
Why “Rip and Replace” Carries More Risk Than It Appears
The appeal of starting fresh is largely psychological. A new system feels cleaner. In practice, however, rebuilding introduces a category of risk that is easy to underestimate:
- Hidden business logic — production systems accumulate rules, edge cases, and workarounds that are rarely documented. Rebuilding means rediscovering them through failure.
- Data continuity gaps — migrating operational data between platforms is rarely clean. Inconsistencies surface after go-live, often in high-stakes workflows.
- User resistance — even a technically superior system will underperform if adoption is low. Familiarity with existing interfaces is a real organizational asset.
- Extended time-to-value — a full rebuild typically delays meaningful AI usage by 12 to 24 months. Augmentation can deliver working functionality in weeks.
The conclusion is not that rebuilds are never warranted, but that augmentation should be the starting position, not an afterthought.
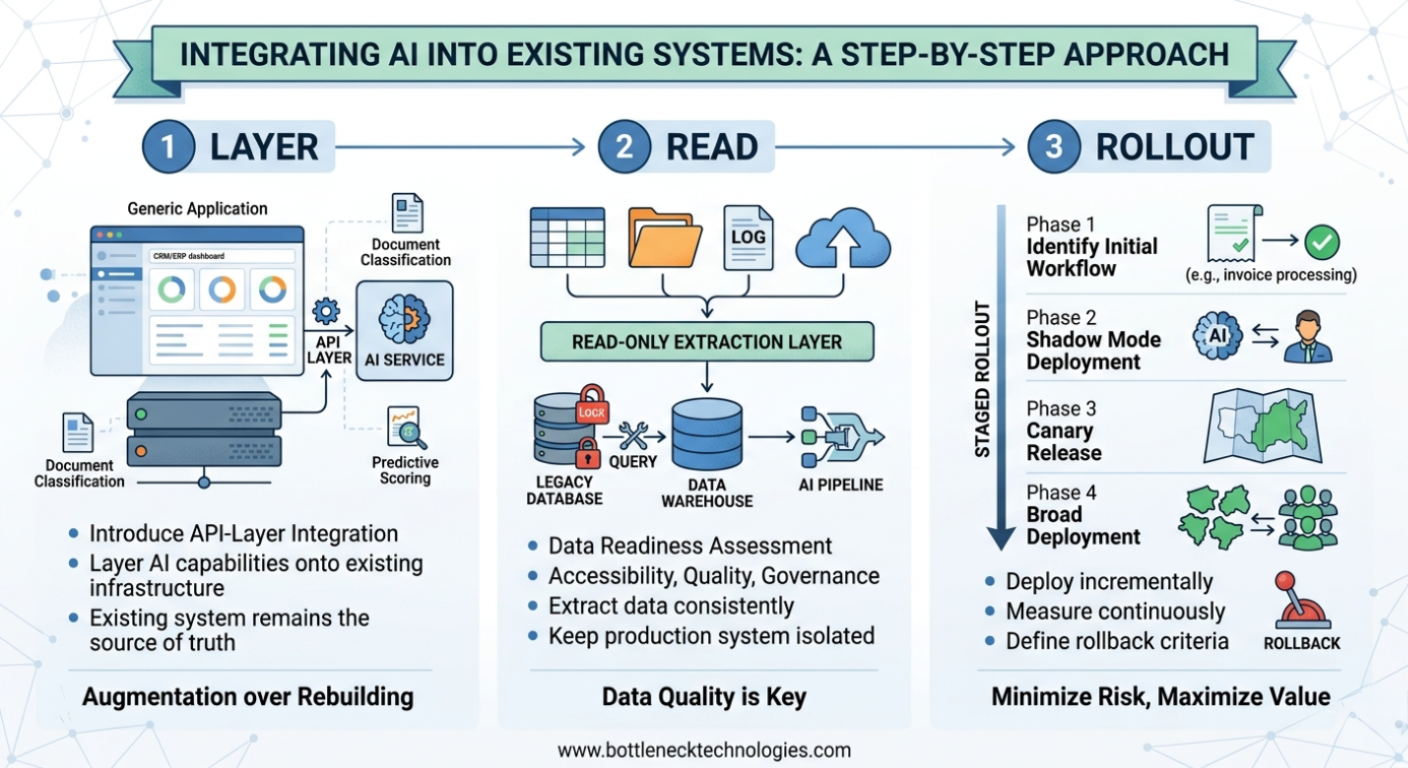
Three Integration Patterns That Preserve Existing Infrastructure
There is no single approach to adding AI to an existing system. The right pattern depends on the platform architecture, data accessibility, and the specific workflow being targeted. The following three models cover the majority of enterprise use cases.
API-Layer Integration
The most common and lowest-risk approach. An API layer is introduced between the existing system and an AI service, allowing the AI to receive data, process it, and return enriched results — without touching the core application. The existing system remains the source of truth; the AI operates as an external service it calls on demand.
This pattern is well-suited for adding capabilities such as predictive scoring, document classification, or anomaly detection to platforms that expose their data via standard APIs.
Sidecar / Overlay Deployment
In cases where modifying the existing system’s API surface is not feasible, an AI component can be deployed in parallel — reading outputs from the live system and presenting a supplementary interface or alert layer. The underlying system continues to operate unchanged. The AI layer processes its data independently and surfaces insights without requiring write access or deep integration.
This model is particularly effective for monitoring-heavy environments, such as operations dashboards or infrastructure management platforms, where the goal is intelligent summarization rather than process automation.
Middleware and Event-Stream Processing
Where multiple systems exist — a CRM, an ERP, logistics platforms, and the challenge is connecting them intelligently rather than modifying any one of them, AI can be positioned in the middleware layer. It processes event streams and data flows as they pass between systems, enriching, routing, or triggering actions based on learned patterns rather than static rules.
This approach is architecturally clean because it avoids point-to-point integrations between individual systems and instead creates a single intelligent layer that all systems interact with.
Data Readiness: The Prerequisite That Cannot Be Skipped
Integration patterns determine how AI connects to existing infrastructure. Data quality determines whether the AI produces anything of value once connected. These are separate concerns, and both must be addressed before deployment begins.
A data readiness assessment should cover three areas:
- Accessibility — can the required data be extracted from the existing system in a structured, consistent format, or is it locked in legacy tables, PDFs, or unstructured logs?
- Quality — are records complete, accurately labeled, and consistently formatted across the time the AI will be trained or evaluated on?
- Governance — particularly in regulated industries (healthcare, financial services, logistics), is sensitive data properly classified, and are there clear policies governing how it may be used within an AI pipeline?
In most cases, data readiness does not require modifying the production system. A read-only extraction layer or a purpose-built data warehouse that feeds the AI pipeline is sufficient — and keeps operational systems entirely isolated from the AI workload.
Deployment Strategy: Staged Rollout Over Big-Bang Releases
One of the more consistent causes of failed AI integrations is attempting to deploy across too many workflows simultaneously. The result is a diffuse implementation that is difficult to monitor, difficult to debug, and difficult to attribute value to.
A staged rollout addresses this directly:
Identify a single high-frequency, high-impact workflow as the initial target. Invoice processing, support ticket triage, and sales pipeline scoring are consistently strong candidates because they are measurable, repetitive, and well-defined.
Deploy in shadow mode first — run the AI in parallel with the existing process, comparing AI outputs against actual decisions without allowing the AI to affect live operations. This builds confidence in the model’s reliability before it takes any consequential action.
Execute a canary release — roll out to a defined subset (one team, one region, one product line) before broader deployment. Contain the blast radius of any issues that surface post-launch.
Define rollback criteria in advance — specify the latency thresholds, error rates, or accuracy benchmarks that will trigger an automatic fallback to the pre-AI workflow. Rollback should be a planned capability, not an emergency response.
Maintaining System Reliability During and After Integration
AI components introduce a new class of dependency into existing architectures. Managing that dependency requires deliberate engineering choices:
Circuit breakers — if the AI service becomes unavailable or returns results below a confidence threshold, the system falls back to its previous behavior automatically. Users experience no interruption; the AI failure is contained and logged.
Resource isolation — containerizing the AI service ensures that computational demands from the AI workload do not affect the performance of the host application. Memory, CPU, and network resources are allocated independently.
Latency monitoring — AI inference adds processing time to workflows that previously had none. Acceptable latency thresholds should be defined upfront and monitored in production, with alerting configured before issues reach end users.
These are not advanced practices — they are standard reliability engineering applied to a new type of component. Any AI integration that does not include them is not production-ready.
Compliance Considerations for Regulated Environments
For organizations operating in regulated industries, AI integration raises legitimate questions about data handling, decision auditability, and vendor oversight. These concerns are manageable, but they must be factored into architecture from the start rather than addressed retroactively.
Key practices include:
Secure, governed data pipelines — data flowing to an AI service should be extracted, anonymized where required, and transmitted through encrypted channels. It should not leave the organization’s governance perimeter without explicit policy authorization.
Explainability requirements — for AI outputs that influence consequential decisions (credit assessments, clinical triage, risk scoring), the model’s reasoning must be auditable. Black-box models are inappropriate in these contexts.
Audit logging — every AI inference, every data access, and every human override should be logged with sufficient detail to satisfy regulatory inquiry.
AI governance framework — define ownership of the AI system, approval processes for model updates, monitoring responsibilities, and escalation paths before deployment. Research consistently shows that organizations with formal AI governance structures experience fewer compliance incidents as they scale.
When Augmentation Is Not Sufficient
To be direct: there are scenarios where augmentation is not viable and a more substantial modernization effort is required. These include situations where:
The existing system has no external API and no practical way to introduce one without destabilizing core functionality
The underlying infrastructure cannot support additional computational workloads without significant degradation
Data quality is so poor that no AI layer can produce reliable outputs without a foundational data remediation effort
In these cases, the appropriate recommendation is not a full rebuild but a targeted modernization of the specific component creating the constraint. Isolating that component, replacing it with a clean, API-accessible service, and then integrating AI onto the modernized layer is almost always lower risk and lower cost than rebuilding the entire platform.
The question is not “rebuild or don’t rebuild” it is “what is the minimum scope of change that creates a viable AI integration path?”
Questions Worth Asking Before Any Integration Begins
Before engaging a development partner on an AI integration, the following questions should have clear, specific answers:
Which single workflow, if improved by AI, would produce the most measurable business impact in the shortest timeframe?
Can the data required for that workflow be accessed from existing systems without modifying production code?
What is the acceptable latency, error rate, and fallback behavior for the AI-augmented workflow?
How will AI outputs be monitored in production, and who owns that responsibility?
What constitutes success at 30, 90, and 180 days — and how will it be measured?
A development partner who cannot answer these questions with specifics before the project starts is not ready to execute it.
In Summary
Adding AI to existing systems is a tractable engineering problem. It does not require organizational upheaval, platform replacement, or tolerance for extended delivery timelines. With the right integration pattern, a clear data readiness assessment, and a staged deployment approach, AI capabilities can be introduced incrementally — delivering measurable value while leaving existing infrastructure intact.
If you are evaluating where AI fits within your current platform, we offer structured discovery engagements to assess your integration options, data readiness, and deployment path. Contact us at contact@bottlenecktechnologies.com to schedule a consultation.
Back
Latest posts


October 8, 2025

August 13, 2025